Amazon Elastic Container Service (Amazon ECS) is a highly scalable, high-performance container orchestration service that supports Docker containers and allows you to easily run and scale containerized applications on AWS.
Autoscaling your container orchestration system introduces some complexity. Here are some tips for creating robust autoscaling for your ECS Cluster.

A brief clarification on some terms:
- Instance
- EC2 Instances; servers hosted by Amazon.
- Task
- Tasks consist of one or more Docker containers deployed to an instance. Task Definitions define what a task looks like. Comparable to what a
docker-compose.ymldefines. - Service
- An ECS Service is where you define how many tasks you want running or how you want to scale them. Like an Autoscaling Group, but for containers.
Scale EC2 Instances On Reservation, Not Utilisation
Your Autoscaling Group (or Spot Fleet) should scale off of reservation instead of utilisation. This is a departure from what is typical in traditional EC2-based applications which scale off of CPU utilisation. When you deploy a service, you have the option to specify CPU and memory reservations for each container. When the service spins up an task, the instance dedicates memory and CPU to that task.
Without reserving resources, we do not limit the number of containers deployed to an EC2 instance. This has obvious performance implications. By reserving CPU and memory for each container, we can guarantee performance for each app, even in a multi-tenanted environment.
Automagic Scaling Policies: Target Tracking
Target Tracking is the 3rd iteration of scaling methods that AWS has created, after Simple Scaling and Step Scaling. All you need to do is plug in a desired number for a metric, and AWS will figure out the rest for you. For example, you can specify that you want 60% MemoryReservation on your ECS Cluster at all times, and AWS will do its best to maintain that number by creating or terminating instances. Although you are forgoing some control over instance creation/termination, it works well for this use case.
One problem with this is that the integration in to Spot Fleet is a bit immature:
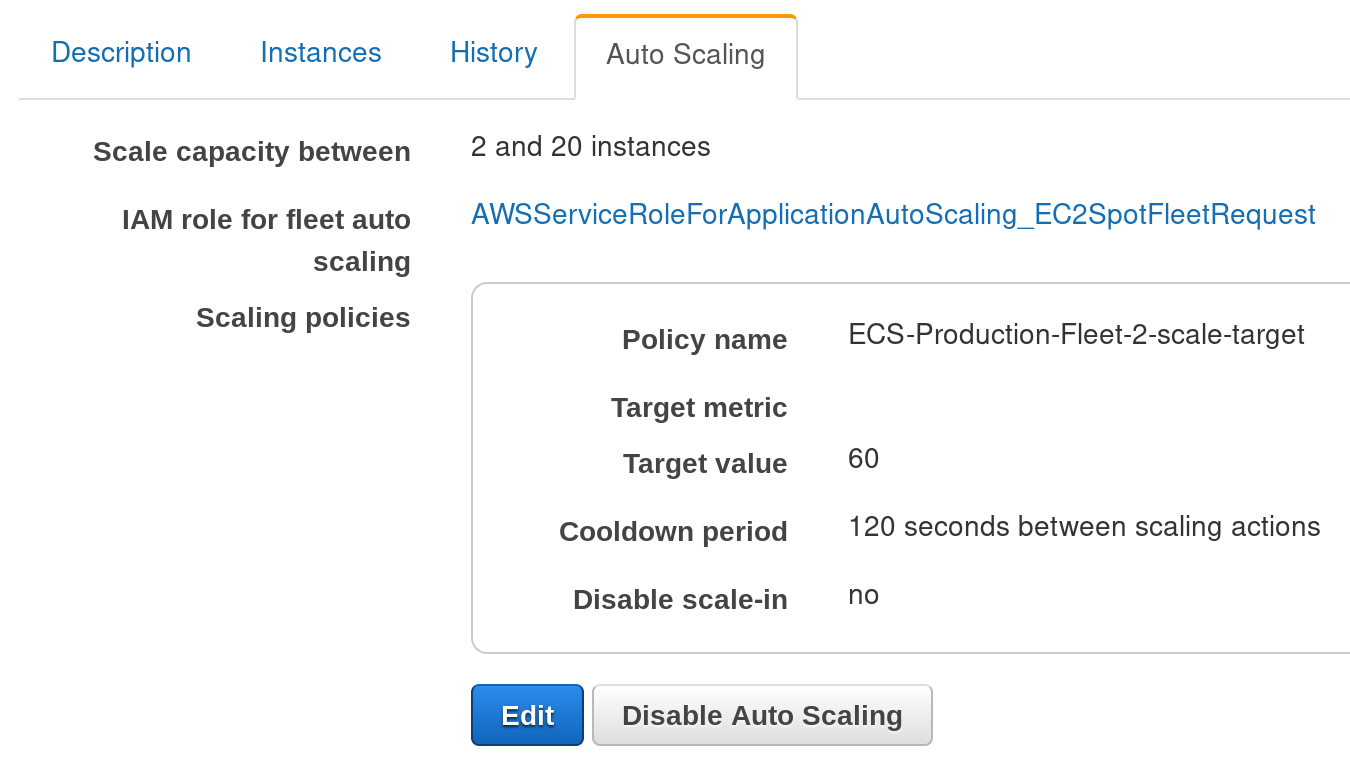
You can't configure it through the console, but CloudFormation works fine:
ServiceScalingPolicyCPU:
Type: AWS::ApplicationAutoScaling::ScalingPolicy
Properties:
PolicyName: !Sub '${AWS::StackName}-scale-cpu'
PolicyType: TargetTrackingScaling
ScalingTargetId: !Ref SpotFleetScalingTarget
TargetTrackingScalingPolicyConfiguration:
TargetValue: !Ref TargetTrackingTargetValue
ScaleInCooldown: !Ref ScaleInCooldown
ScaleOutCooldown: !Ref ScaleOutCooldown
CustomizedMetricSpecification:
MetricName: CPUReservation
Namespace: AWS/ECS
Statistic: Average
Dimensions:
- Name: ClusterName
Value:
Fn::ImportValue: !Sub "ecs-${ClusterName}-ECSCluster"
ServiceScalingPolicyMemory:
Type: AWS::ApplicationAutoScaling::ScalingPolicy
DependsOn: ServiceScalingPolicyCPU # Spot Fleet requires that we create scaling policies sequentially
Properties:
PolicyName: !Sub '${AWS::StackName}-scale-memory'
PolicyType: TargetTrackingScaling
ScalingTargetId: !Ref SpotFleetScalingTarget
TargetTrackingScalingPolicyConfiguration:
TargetValue: !Ref TargetTrackingTargetValue
ScaleInCooldown: !Ref ScaleInCooldown
ScaleOutCooldown: !Ref ScaleOutCooldown
CustomizedMetricSpecification:
MetricName: MemoryReservation
Namespace: AWS/ECS
Statistic: Average
Dimensions:
- Name: ClusterName
Value:
Fn::ImportValue: !Sub "ecs-${ClusterName}-ECSCluster"
Note that we're scaling on both memory and CPU. Target Tracking will match the higher of the two metrics, preventing infinite scaling loops when both metrics are in breach in the opposite direction.
Reserve Enough Reservation For Scaling/Deployments
It may be tempting to try and achieve a high reservation utilisation across your ECS Cluster. If you had an average of 90% reservation across your ECS Cluster, it would mean you were getting awesome cost efficiency --- probably a magnitude higher than you would with normal EC2 instances set to scale at 50% CPU.
The problem with this is that it can cause deployments and scaling to fail. When ECS tries to deploy new tasks, it tries to find an instance with sufficient free capacity (free reservation).
If ECS fails to find a suitable instance, it fails and does nothing.
ECS logs the error to the service's event section, but ECS does not automatically deploy additional EC2 instances to create free capacity. Even if we create additional capacity, ECS makes no attempt to retry to the deployment.

Workarounds exist 1 2 3, but the best approach is to avoid this problem by always having enough capacity to deploy. In practice, you may need up to 40% capacity free at all times, especially if you are doing blue/green deployments.
Another thing to note is that the larger your cluster is, the less likely you are to have issues with spare capacity.
Deploying Memory Hogs
Another thing to look out for is having enough spare capacity to deploy the largest task in your ECS Cluster. Although you may have enough total reservation free across the cluster, it may be spread across several instances. A situation can arise where there is no single EC2 instance with capacity to deploy a large application, even though the cluster has plenty of reservation to spare.
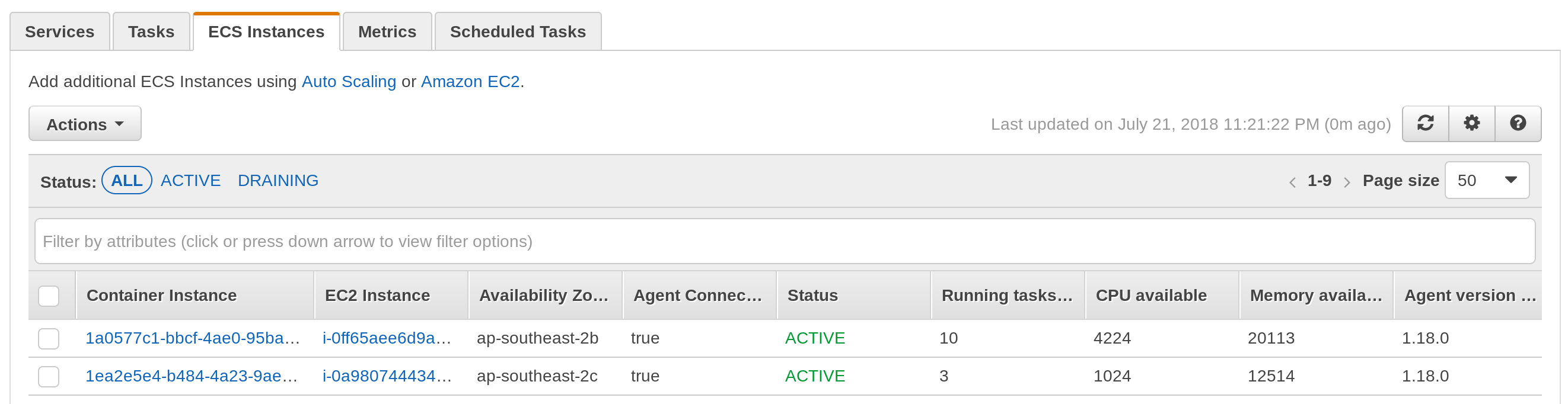
Although this cluster as a whole has at least 5000 CPU units to spare, a task that requires it will fail to deploy.
A solution to this is to use the binpack placement strategy. This ensures that ECS fills up each instance (as much as possible) before it deploys to the next instance. We can even use the AZ spread strategy at the same time to ensure that we have redudnancy across AZs before binpacking on to a single instance.
ECService:
Type: AWS::ECS::Service
Properties:
PlacementStrategies:
- Type: spread
Field: attribute:ecs.availability-zone
- Type: binpack
Field: memory
# ...
Again, the larger your cluster is, the less likely you are to have this issue.
ECS Rebalancing
One concern I had is that by following the binpack strategy, we would effectively always have an instance in each AZ that was idle. Remember that CPU reservation is a soft limit; if compute is not reserved or being used, then containers can freely use it. It's only when resources come under contention that the CPU limits are applied to containers. Therefore, wouldn't it be better to ensure that some containers are deployed to every instance? At least that way, the otherwise idle instances were getting some use.
However, in practice this is not the case. Unlike Autoscaling Groups, ECS Services do not rebalance automatically 4 5. If you are regularly recreating your instances or services due to autoscaling or deployments, you will never achieve perfect binpacking and there will almost always be a natural spread of containers.
Use Spot Fleet For Production Critical Workloads
Spot Fleet savings are amazing, and since your application is 12 factor, having an instance suddenly shut down is no problem. Make sure you use a few different instance classes (and even generations) and there is no reason to not use spot instances, even in production. Especially in production!
You will want to deploy connection draining to prevent dropped connections when your spot instances get terminated.
Spot Fleet Allocation Strategies
I briefly experimented with using the lowestPrice allocation strategy in combination with instance weighting by number of vCPUs. In theory, Spot Fleet would automatically determine which instance type/size provided the cheapest vCPU. This is ideal when our applications just see ECS as a pool of resources and the individual instance types are completely abstracted.
In practice, this doesn't really work because Spot Fleet does not take in to account the actual capacity you need, and always deploys the cheapest per-weighting instance type. Even if you only need an additional 2 vCPUs, Spot Fleet will deploy a c5.4xlarge (16 vCPUs) because it has the best vCPU:cost ratio. Because of this, it ended up being cheaper to run using the diversified allocation strategy.
One solution to this may be the InstancePoolsToUseCount option, but it doesn't look like this is available in CloudFormation yet.
Container Autoscaling
Finally, we arrive at the container layer! Now that we have a ECS Cluster that will scale to meet any demand we throw at it, we can scale our containers on utilisation.
Target Tracking also works well here. A nice feature is the ability to set multiple metrics to scale on, and Target Tracking will scale to meet the highest one. For example, you may set your application to scale at 60% CPU and 90% memory utilisation. This ensures that your application is not bottlenecked by either resource.
ServiceScalingPolicyCPU:
Type: AWS::ApplicationAutoScaling::ScalingPolicy
Properties:
PolicyName: !Sub '${AWS::StackName}-scale-target-cpu'
PolicyType: TargetTrackingScaling
ScalingTargetId: !Ref 'ServiceScalingTarget'
TargetTrackingScalingPolicyConfiguration:
TargetValue: 60
ScaleInCooldown: 180
ScaleOutCooldown: 60
PredefinedMetricSpecification:
PredefinedMetricType: ECSServiceAverageCPUUtilization
ServiceScalingPolicyMem:
Type: AWS::ApplicationAutoScaling::ScalingPolicy
Properties:
PolicyName: !Sub '${AWS::StackName}-scale-target-mem'
PolicyType: TargetTrackingScaling
ScalingTargetId: !Ref 'ServiceScalingTarget'
TargetTrackingScalingPolicyConfiguration:
TargetValue: 90
ScaleInCooldown: 180
ScaleOutCooldown: 60
PredefinedMetricSpecification:
PredefinedMetricType: ECSServiceAverageMemoryUtilization
For optimal scaling, set ScaleOutCooldown as low as possible a value, but high enough that a new container has enough time to impact the average of the metric that it's scaling on. Set ScaleInCooldown much longer to prevent flapping.
Enforce Reservations On ECS Services
Without reserving resources on an ECS Service, containers can be in contention for resources, resulting in unpredictable behaviour. All ECS Services should have both memory and CPU reservations. If an application has a sidecar container, you should also allocate an appropriate percentage of those resources to the "essential" container, or you risk the sidecar consuming too many resources and causing service degradation.
Note here how we've reserved the majority of the CPU (700) and memory (1536) for the "Web-App" container in this task definition:
{
"containerDefinitions": [
{
"essential": true,
"image": "myorg/webapp:latest",
"name": "Web-App",
"cpu": 700,
"memory": 1536,
"portMappings": [
{
"containerPort": 80
}
]
},
{
"image": "myorg/sidecar:latest",
"name": "Sidecar",
}
],
"family": "Web-App-${ENV}",
"volumes": [],
"memory": "2048",
"cpu": "1024"
}
Minimise Per-Container Reservations
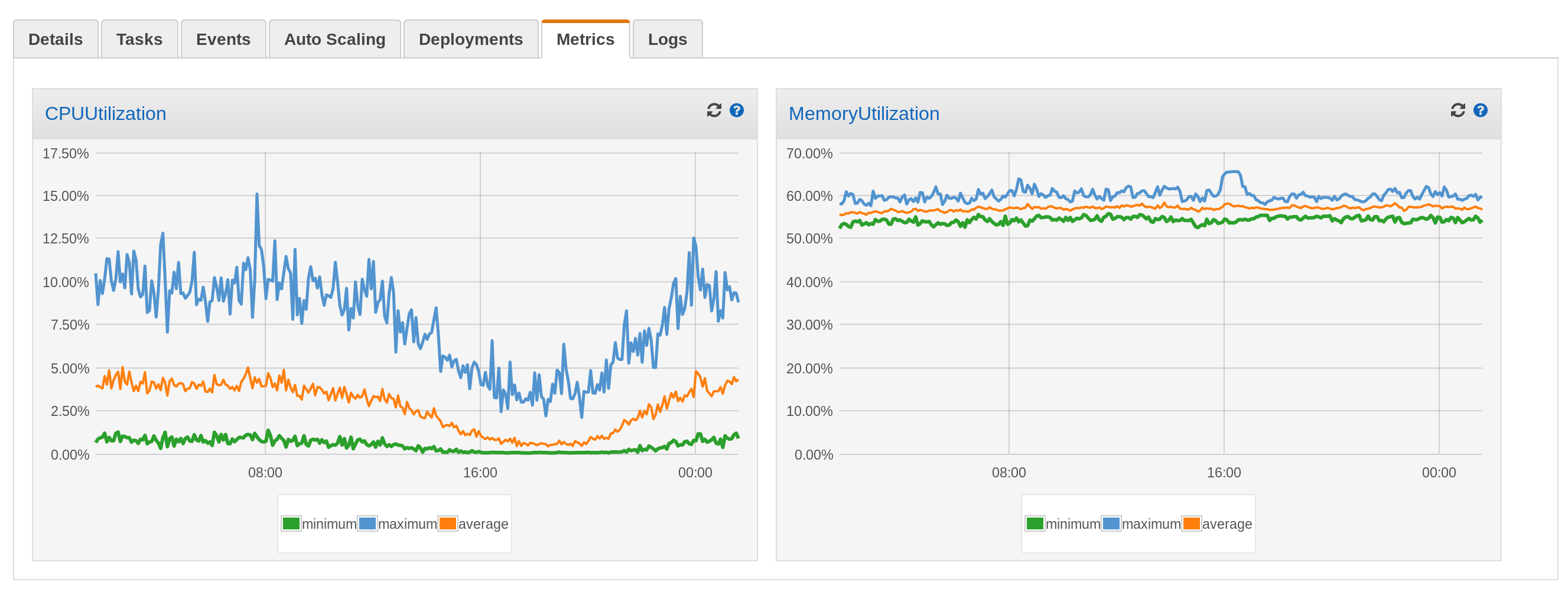
Keep containers as small as possible to ensure smooth scaling and deployment. The smaller your containers are, the closer you are to optimal resource efficiency and the less likely you are to have issues deploying new tasks.
Reducing resources allocated to each task does not mean your application will be less responsive. Each container still needs to be able to handle baseline load. The difference is that when introducing load beyond that, we don't need to spec a single container to be able to handle it --- ECS will spin up additional tasks with autoscaling.
Conclusion
To create a stable ECS platform, we need the following:
- Scale instances on both memory and CPU reservation
- Allow a sufficient buffer for scaling and deployments
- Configure reservation on all tasks
- Prefer many smaller containers to few large ones
With this, we now have a platform that rivals Fargate in its ability to scale, but at 1/10th 6 of the cost.
-
https://medium.com/prodopsio/how-to-scale-in-ecs-hosts-2d0906d2ba ↩︎
-
https://garbe.io/blog/2017/04/12/a-better-solution-to-ecs-autoscaling/ ↩︎
-
https://github.com/aws-samples/ecs-refarch-task-rebalancing ↩︎
-
Heroku vs ECS Fargate vs EC2 On-Demand vs EC2 Spot Pricing Comparison shows that a Spot m5.xlarge is 1/14th the price of an equivalent Fargate task. ↩︎