Exploring GitLab's new Directed Acyclic Graph feature to build monorepo CI/CD pipelines.

In mathematics, particularly graph theory, and computer science, a directed acyclic graph is a finite directed graph with no directed cycles.
In the context of GitLab pipelines, a DAG is chain of jobs created by specifying the dependencies between jobs. This is in contrast to grouping jobs by stage, which allows for parallelisation of jobs but does not permit the creation of multiple CI/CD pipelines in a single repository.
Scenario
The examples below demonstrate an infrastructure deployment, specifically the Elasticsearch, Kibana and Fluent Bit (EFK) stack. It uses Helm to deploy to Kubernetes, as well as some infrastructure components using Terraform. It assumes Trunk-Based Development (optionally with short-lived feature branches). Feature branches/merge requests will perform helm diff and terraform plan to sanity check changes before deploying.
The principles described here are not specific to any technology; this can apply to backend application development, frontend, Infrastructure as Code, or all of the above.
Why Multiple Pipelines?
With a git repository that contains a single component, the pipeline is quite easy to describe using stages:
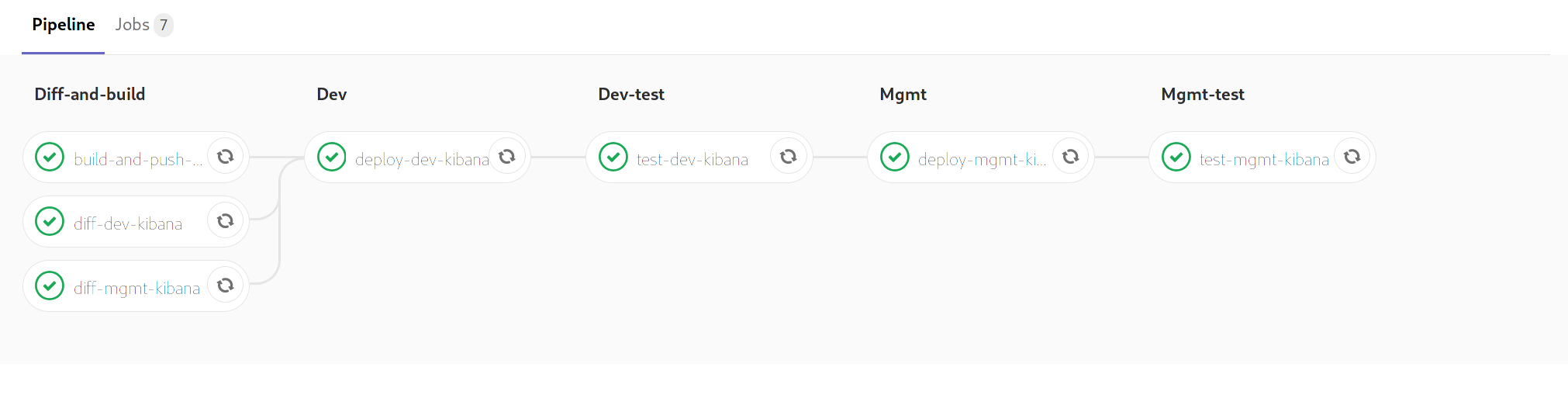
The pipeline flows in one direction, ensuring the each stage is fully complete before moving on to the next one. This is still quite flexible if you need to execute several jobs per stage; for example:
- Diff and build jobs in a single stage. Both jobs can run in parallel as they do not have any dependency on each other to execute. The next stage ("Dev") will always require all jobs from the "Diff" stage to complete.
- Deployments to multiple regions in a single environment (not pictured). If the risk profile is similar for each region (and you do not have any complex strategies like canary deployments) you can speed up the pipeline by executing them in parallel. If either of these deployments fail you will likely want to completely halt the pipeline to fix the issue before proceeding to further environments.
Note that this is still a single pipeline, even with parallel jobs. All jobs are mandatory and are tightly coupled -- you cannot deploy to Kubernetes without building a Docker image, for example.
Why would I need multiple pipelines then? The need for multiple pipelines arises from a repository that has multiple, decoupled components -- in other words, a monorepo.
For example, our hypothetical monorepo structure:
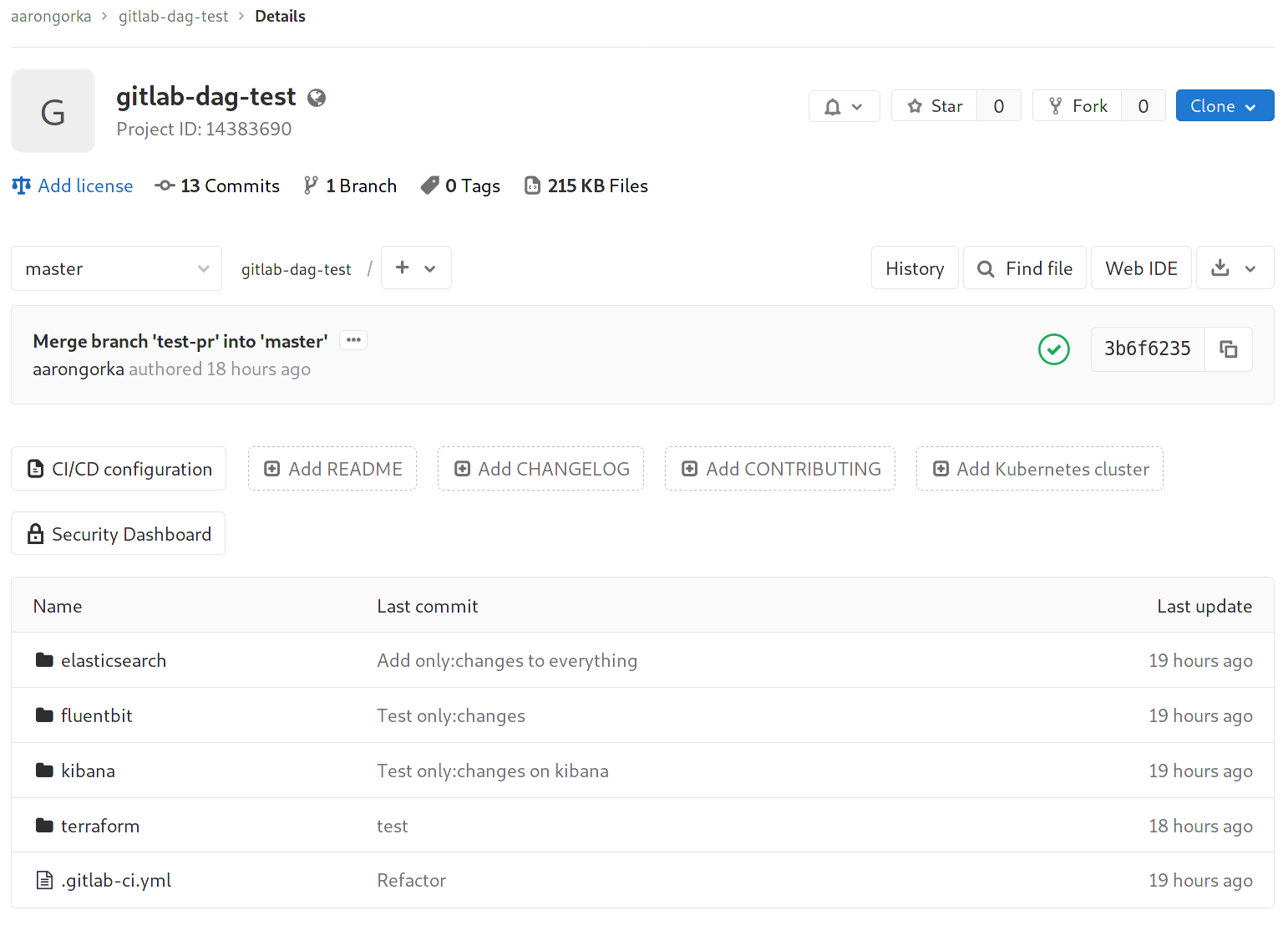
In it, we have 4 decoupled components to deploy. There are interactions between them -- they exist as part of one system (log analytics) -- but they can be deployed independently without affecting one-another.
By deploying them separately, there is less risk when making changes. This is the basis of microservices; small, decoupled components that can be deployed independently.
And to do this, we need multiple pipelines in a single repository.
Structure
First, we will use the include: feature to separate each pipeline in to separate files.
Stages still need to be defined but technically do not affect execution if needs: is specified on every job.
Top-level .gitlab-ci.yml:
---
stages:
- diff-and-build
- ops
- dev
- dev-test
- preprod
- mgmt
- mgmt-test
- prod
include:
- '/elasticsearch/.gitlab-ci.yml'
- '/fluentbit/.gitlab-ci.yml'
- '/kibana/.gitlab-ci.yml'
- '/terraform/.gitlab-ci.yml'
DAG
GitLab could have implemented multiple pipelines per repository any number of ways. Interestingly, GitLab decided that DAGs provided the most flexible way of implementing multiple pipelines per repository.
To build a Directed Acyclic Graph, add the needs: keyword to jobs in the pipeline.
.gitlab-ci.yml for Kibana:
build-and-push-kibana:
stage: diff-and-build
environment:
name: docker-kibana
script:
- echo "Building a Docker image!"
# no `needs:` here, nothing comes before this!
diff-dev-kibana:
stage: diff-and-build
script:
- echo 'Running helm diff...'
diff-mgmt-kibana:
stage: diff-and-build
script:
- echo 'Running helm diff...'
deploy-dev-kibana:
stage: dev
environment:
name: dev-kibana
script:
- echo 'Running helm upgrade...'
only: [ master ]
needs: # require all Kibana-related jobs from the `diff-and-build` stage to pass
- build-and-push-kibana
- diff-dev-kibana
- diff-mgmt-kibana
test-dev-kibana:
stage: dev-test
script:
- echo 'Running smoke test...'
only: [ master ]
needs: # require only Kibana deployment from dev - not Elasticsearch or Fluent Bit
- deploy-dev-kibana
deploy-mgmt-kibana:
stage: mgmt
environment:
name: mgmt-kibana
script:
- echo 'Running helm upgrade...'
only: [ master ]
needs:
- test-dev-kibana
test-mgmt-kibana:
stage: mgmt-test
script:
- echo 'Running smoke test...'
only: [ master ]
needs:
- deploy-mgmt-kibana
Elasticsearch has a very similar looking .gitlab-ci.yml. FluentBit (a log shipper for Kubernetes) is deployed to many clusters (Elasticsearch is centralised and collects logs from many clusters) so it has more stages. Terraform is only required for Elasticsearch and has no system tests, so it only has two stages.
A full example can be found here: https://gitlab.com/aarongorka/gitlab-dag-test
The technical implementation is not so important here; the point is that even though several components share the diff-and-build stage, the deploy-dev-kibana job will only consider the success/failure of the 3 jobs listed under its needs:.
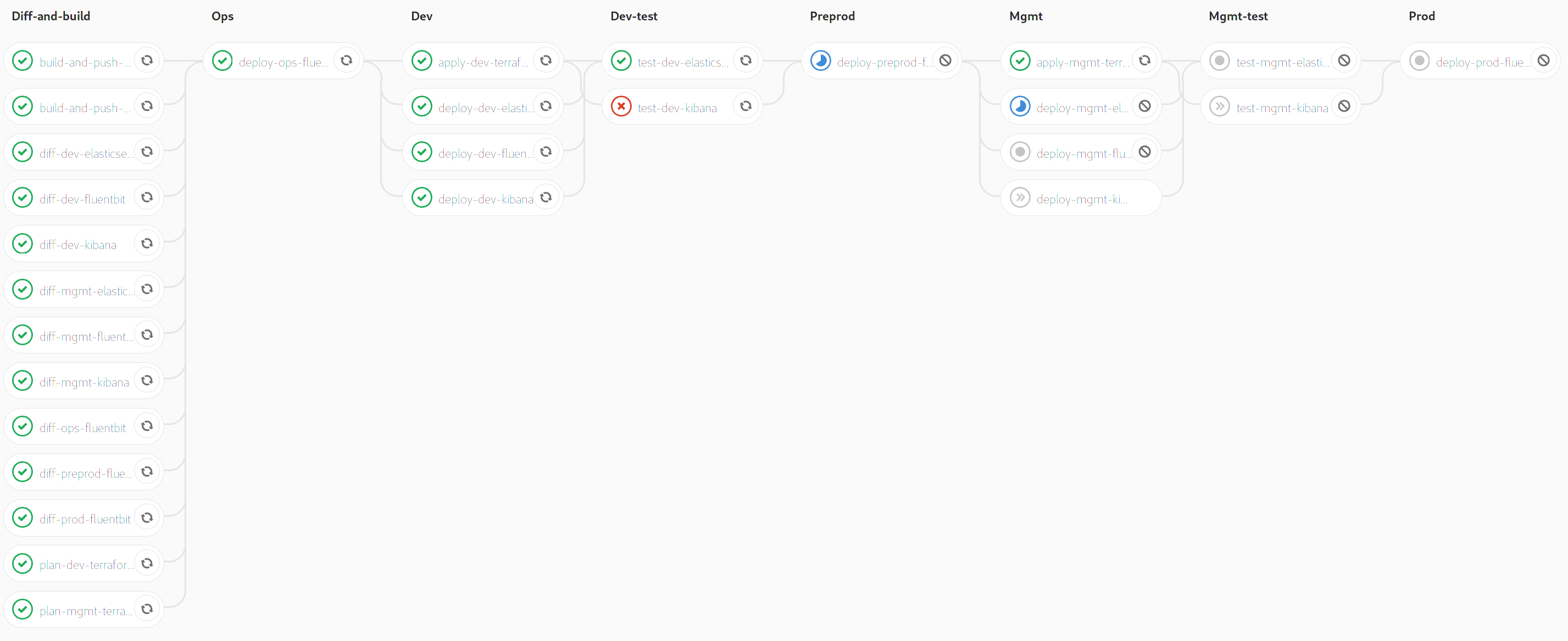
Triggering the pipeline shows that each component is deploying indepenently:
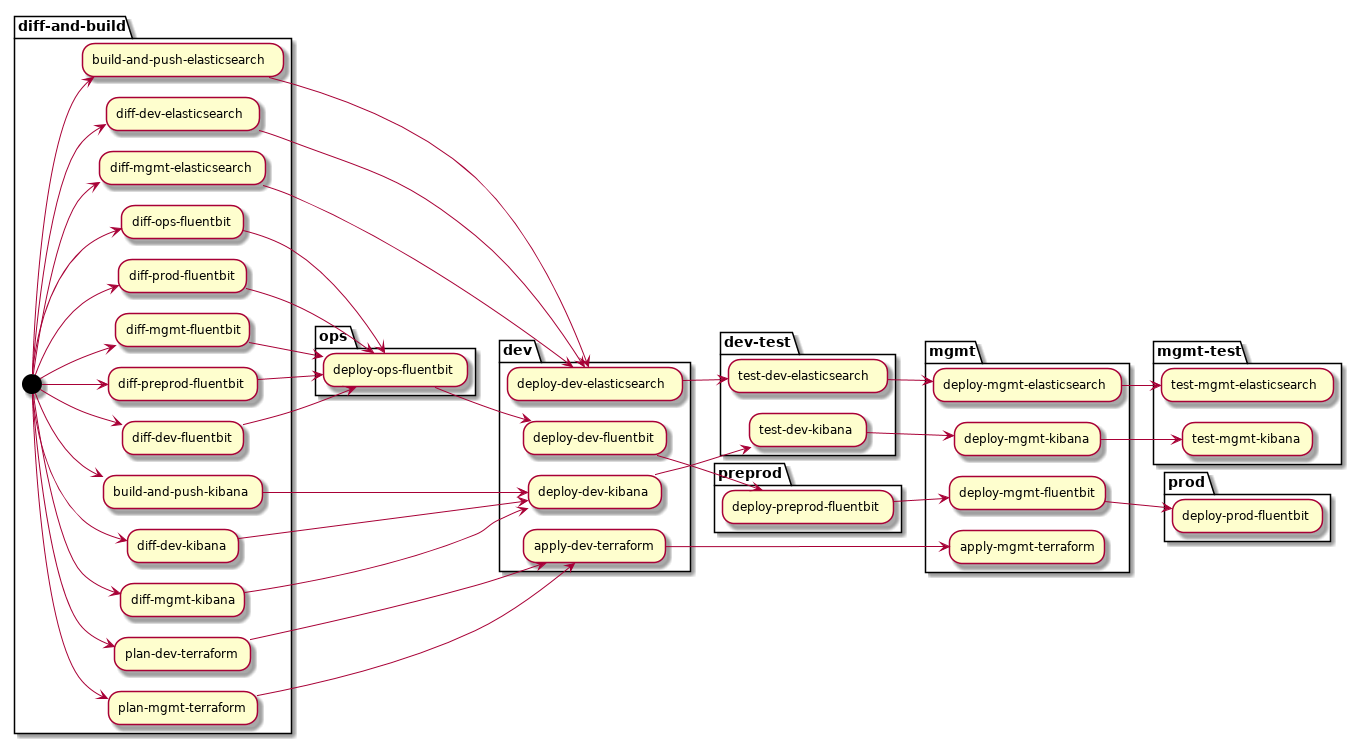
Visualisation
The GitLab UI has not been updated to show the relationships between stages when using the needs: feature, and debugging without this can be a bit tricky. I'm sure that it will be updated at some point, but until then we can easily generate a diagram using PlantUML and some hacky Python code.
Just run this script in the root directory of your repository, and it will print PlantUML diagram. You can then take the output and render an image using one of these handy websites:
This will render the DAG like so:
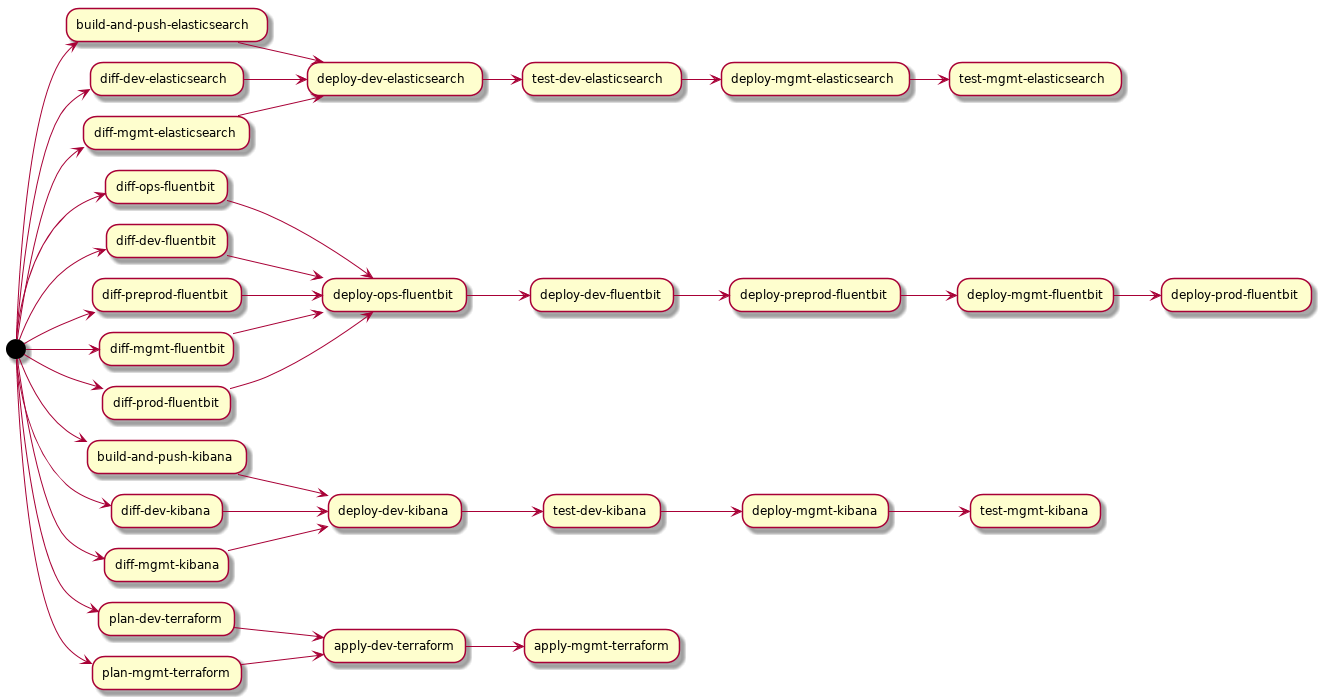
I also experimented with grouping by stages; this isn't technically accurate as stages have no bearing on execution when using needs: but it does look nice:
Selectively Running Pipelines
So far we have demonstrated a working monorepo configuration. When we push code, each pipeline will be invoked and will run independently of one-another.
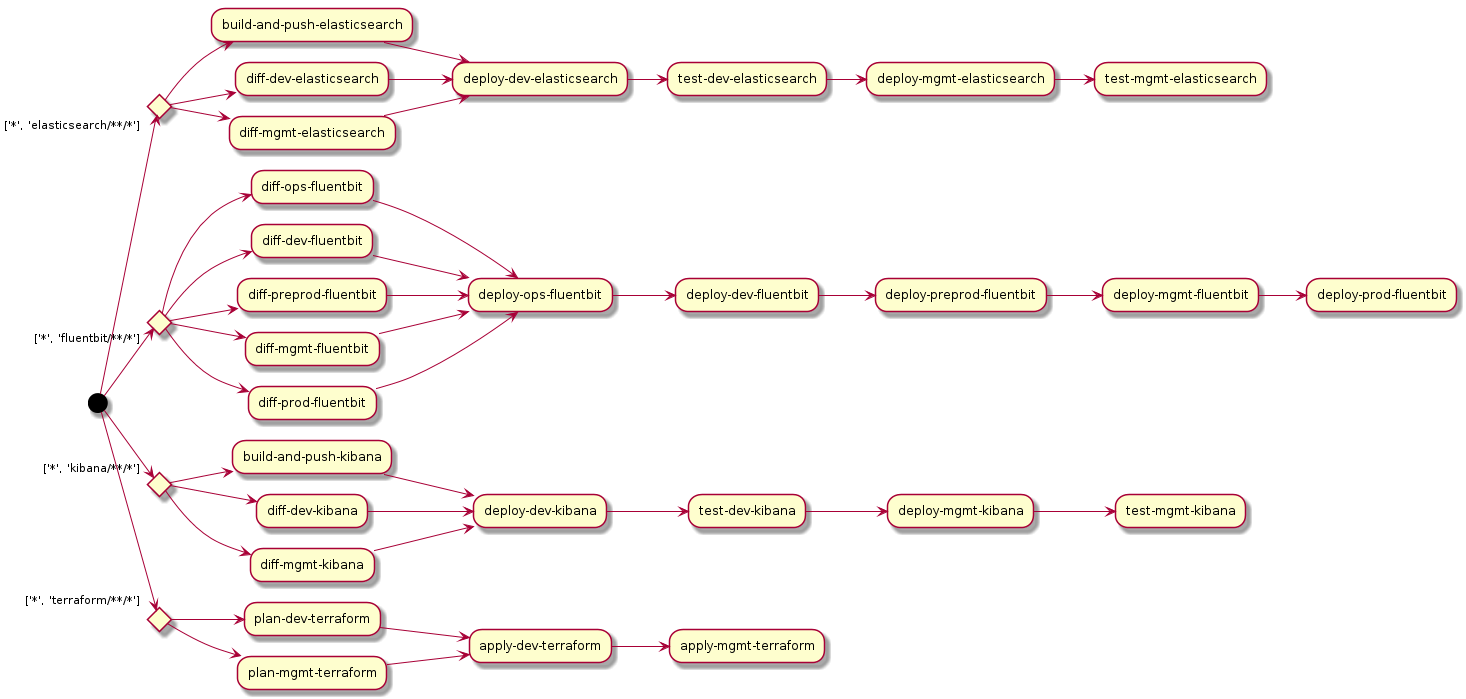
We can enhance it further by only having the affected pipelines run when a commit is pushed. There is no reason to run the elasticsearch/.gitlab-ci.yml pipeline if the commit only changes files under kibana/.
We can achieve this by using the only:changes feature.
Feature branch stage:
build-and-push-kibana:
only:
changes:
- "*" # run pipeline if a root-level file like Makefile or docker-compose.yml is changed
- "kibana/**/*" # run pipeline if any files under kibana/ have changed
Master-only stage:
deploy-dev-kibana:
only:
refs:
- master # only run if there are changes and we're on master branch
changes:
- "*"
- "kibana/**/*"
needs:
- build-and-push-kibana
- diff-dev-kibana
- diff-mgmt-kibana
Now, commits that only affect a select component in the repository will trigger pipelines for those components only. Here is an example where I merged a change to master which only changed a Terraform file under terraform/:
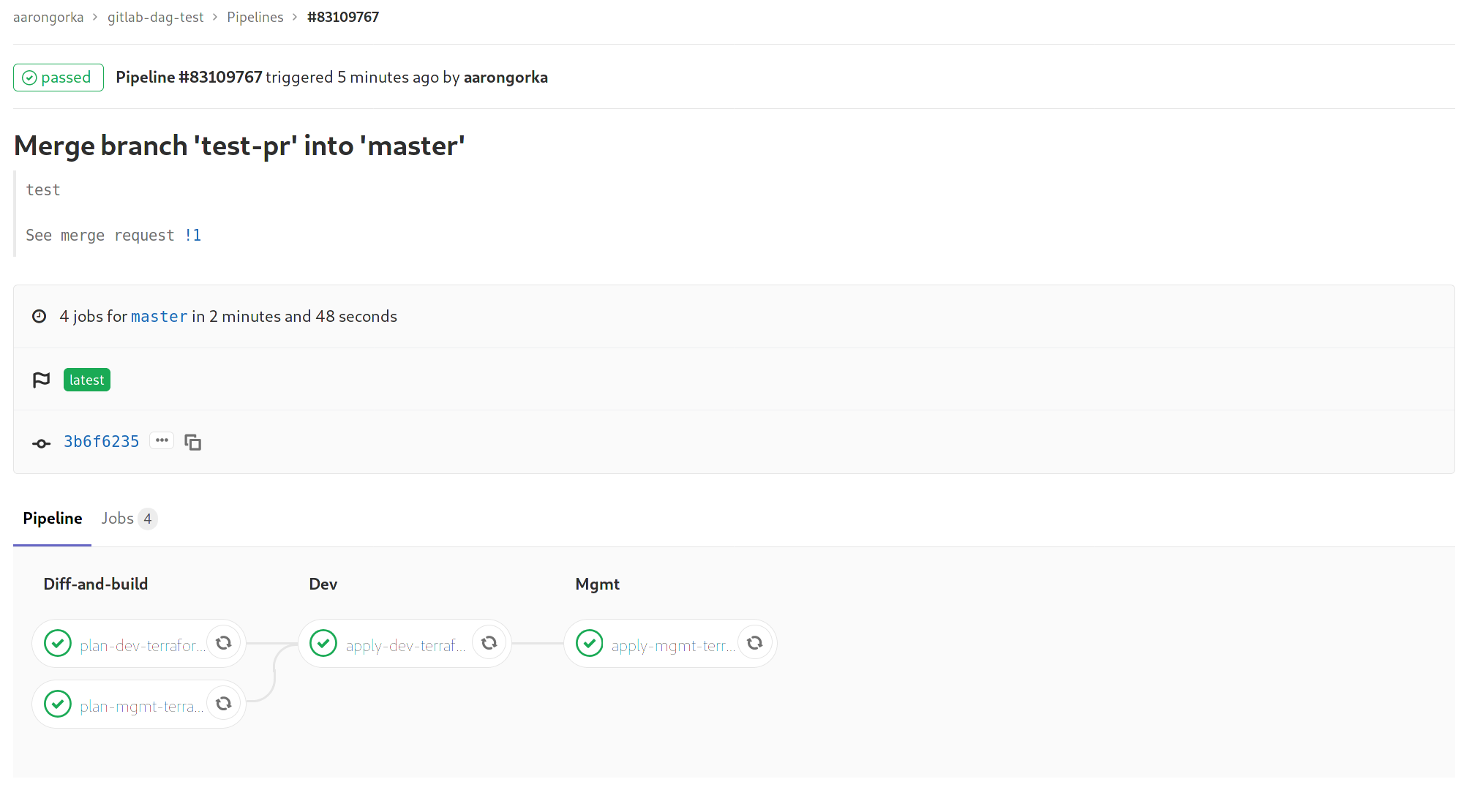
Note that branch creation will always run all pipelines because GitLab doesn't know what to diff the branch against.

Finally, we can render the conditionals in the PlantUML diagram:
Gotchas
Skipping Jobs
A job with needs keyword is run even if needed job is skipped
https://gitlab.com/gitlab-org/gitlab/issues/31526
This one is pretty bad. It means that a pipeline can continue executing upon failure (you had one job, pipeline!). A "deploy dev" job can fail, skip "test dev" and go straight to "deploy prod". The workaround is to explicitly add all transitive dependencies to needs:. However this may not be realistic as it adds a lot of bloat and compexity to the yaml files and there's also a limit on how many needs: you can have on any one job. Hoping it gets fixed quickly!
Limit on needs:
Note that one day one of the launch, we are temporarily limiting the maximum number of jobs that a single job can need in the needs: array.
https://gitlab.com/gitlab-com/gl-infra/infrastructure/issues/7541
As of writing, the limit of jobs you can have in needs: is 5, so you need some workarounds in scenarios with e.g. a lot of diffs occurring. The best workaround I've found so far is to move some of the dependent jobs to a job further upstream -- not perfect but good enough until the limit is increased.
Complexity
I can see complexity becoming an issue with large monorepos. Even in our simple demo the pipelines are quite hard to follow from the yaml files alone and we need to rely on visualisation to debug them. I agree with GitLab that Directed Acyclic Graphs are the most accurate way to represent a CI/CD pipeline, but I can also see the temptation to over-engineer with DAGs.
I'm also wary of using a DAG to define the order in which components need to be stood up. In the earlier example, you could make Elasticsearch dependent on Terraform as it is a prerequisite for Elasticsearch. I've not had enough experience with monorepos to say for sure, but I suspect that this is an antipattern for two reasons:
- It tightly couples the deployment of the two components and prevents you from separating their pipelines
- It greatly increases the complexity in the graph, potentially to the point where the visualisation output from the script earlier becomes difficult to interpret
I'm not sure what best way to handle initial deployment ordering (pre-deploy checks? temporary dependencies? temporary manual gates?), but this ain't it.
Conclusion
GitLab DAGs, when combined with include: and only:changes are a great way to implement CI/CD pipelines for monorepos; with a few caveats that will hopefully be fixed as the feature matures.