This blog entry is the story of my experience in implemeting a CMS as a consultant. It details some mundane problems I faced in day-to-day work and the solutions that my team and I implemented, probably in more detail than necessary. I make no attempt to avoid the boring and tedious parts of the project. Maybe you can learn something from it, or maybe you can relate to it.
For context, I am taking the position of a Cloud Architect, tasked with providing "expert advice" on optimal cloud architecture for the implementation of a new Content Management System (CMS). I end up getting heavily involved with the implementation details of this CMS - as well as some of the supporting systems.
I've joined relatively late in the project and decisions (that are basically impossible to undo) have already been made. There is a transformation initiative within the organisation, to become "cloud-native".
So it begins: what is needed to implement this project in a cloud-native fashion?
StatefulSets in ASGs
The first consideration is a common one; state. Life is easy when everything is stateless, or even when you can offload some of it to your cloud provider. The CMS that we're working with here permitted no such thing, as it stored everything on disk. As all good applications from the 90's should. It has absolutely no RDBMS support we can use to offload the difficult parts of storage to. It's also clustered, but only sort of; there's no replication between the nodes.
In short, we need a solution that allows you to store files on disk, but we also want something that will enable us to have all the benefits of a cloud-native application such as rolling updates and self-healing.
As someone who has worked with Kubernetes, I figured this was a common usecase to StatefulSets. StatefulSets are the least-worst solution to running stateful applications as they at least try to give you the best of both worlds; the ability to run legacy/stateful applications as well as some of the capabilities we've come to expect from a cloud-native world.
But we're not using Kubernetes. Kubernetes is nowhere near this project, and it never will be. But it's not really Kubernetes specifically that I needed, it was just the concept, the paradigm behind StatefulSets. What if we could implement StatefulSets in AWS?
We'll need two things:
- Index orchestration
- Persistent storage
Index Orchestration
If we're launching instances in an ASG, we'll need to give them indexes. Each pod in a StatefulSet is assigned a number e.g. between 1-4, with each index always receiving the same storage and DNS entry even if the underlying pod changes. We needed something to assign indexes to instances when they launched, hence "index orchestration".
The process is as follows:
- Instance is launched
- Userdata executes
index_orchestration.py - Determine which indexes in the set of
[1, 2, 3, 4]are currently allocated via boto3'sclient.describe_instances() - Determine how many instances are waiting to be allocated an index, backoff if there are too many
- If the instance does not have an index assigned, create a tag on the instance
- Create a DNS record with the index in it pointing directly to the instance
Initially this solution was provided by a Lambda that watched scaling events, but because the solution was so heavily dependent on it, it had to be synchronous so that the proceeding scripts could rely on it existing.
While this wasn't hard to get up and running, there were many edge cases where we hadn't considered permutations of the various states that the ASG could be in, such as multiple instances waiting for an index, or the ASG incrementing the desired count above the amount of available indexes during rolling updates. One workaround for this was to tag the ASG with the maximum number of indexes (4) rather than relying on the desired count to accurately reflect this.
Persistent Storage
Now that we have indexes assigned to each instance, we need to find a way to consistently assign storage to each instance. There's one problem: you can't attach volumes cross-availabity zone (AZ), and there's no way to predict what AZ an instance will launch in when it's managed by an ASG.
Persistent storage is achieved for the StatefulSet ASG by using https://github.com/aarongorka/ebs-pin. It enables an EBS snapshot to "float" between AZs by taking snapshots and recreating the volume when necessary.
Painfully, the CMS did not have any kind of properly defined separation between application code and state. While there was a directory that held most of the state, some files outside of this directory were also modified during install. Therefore, the application needed to be (re)installed on every single boot. This significantly increased the boot time and subsequently, the deploy time.
To make matters even worse, patches for this application required a reboot before taking affect. Patched versions of the application were not available, all updates needed to be installed as in-place patches. This even further increased the boot/deploy time (more on that later).
Some challenges were had here around being able to clean up volumes/snapshots; specifically the requirement to clean up snapshots when tags were added or removed between deployments, but not to cleanup the backups which inherited the tags of the volume. The logic was complex enough that I found it easiest to write up a matrix of scenarios in which a given snapshot would be cleaned up based on, and then come up with the logic that operated on the union of existing and desired tags:
def test_can_delete_snapshot(self):
# tags on snapshot # tags known by CLI (ebs-pin)
assert ec2.can_delete_snapshot(["Team"], ["Name", "UUID", "Team"]) == False # not ebs-pin, can't delete
assert ec2.can_delete_snapshot(["Name", "UUID", "Team"], ["Name", "UUID", "Team"]) == True # the same, can delete
assert ec2.can_delete_snapshot(["Name", "UUID", "Team", "Backup"], ["Name", "UUID", "Team"]) == False # has backup tag, can't delete
assert ec2.can_delete_snapshot(["Name", "UUID", "Backup"], ["Name", "UUID"]) == False # has backup tag, can't delete
assert ec2.can_delete_snapshot(["Name", "UUID", "Backup"], ["Name", "UUID", "Team"]) == False # has backup tag, can't delete
assert ec2.can_delete_snapshot(["Name", "UUID"], ["Name", "UUID", "Team"]) == True # CLI has new tag, can delete
What if we could implement StatefulSets in AWS?
The solution definitely worked in concept, and it mostly worked in practice, but it missed the nuances of the application; the lack of separation between code and configuration, the inability for the application to handle moving data across different machines. You couldn't say it outright didn't work, but there also wasn't a lot of confidence in it.
Deterministic Startup
cfn-signal
To allow for continuous deployment of the application, a reliable and deterministic method of deploying applications and the ability to know when the application had finished booted. The standard approach for this when dealing with ASGs is a combination of:
In short, this achieves a similar deployment strategy to Kubernete's rolling update. The caveat here is that cfn-signal does not automatically wait for healthchecks to pass, it fires immediately at the end of the script. Any logic that is used to determine whether the application has finished booting needs to be implemented ourselves.
poll_tg_health.py
A simple script, it finds the TG (Target Group) for the calling instance and waits for the healthchecks for that instance to be "in service".
This is important because it closes the gap between the time it takes for your application to start up, and the draining period of the previous instance that's being terminated. Your application takes too long to boot? You've now got one unhealthy instance (according to the load balancer) and one instance that's being terminated (and draining, therefore serving no inbound requests). So, we wait for the current instance to finish healthchecks on the load balancer before firing cfn-signal and moving on to the next instance.
Implementing this was relatively painless, the only mildly inconvenient part being that there is no convenient API for finding the TG for an application, and that 2 TGs may exist at the same for a stack when the TG needs updating (replacing), necessitating quite a few API calls.
This is a strategy I have used before and will continue to use for any future projects that run on ASGs. Deployments should be as deterministic as possible, wait for all healthy signals and immediately fail at any sign of something not working.
Waiting for the CMS to start
The CMS that we're dealing with is quite unusual for an application that needs to be run in the cloud. It:
- Has no API to tell whether it has started
- Does not know itself when it has started
- Does not reliably start at all
- Does not reliably fail in the same way when it doesn't start
- Does not reliably fail, can get stuck indefinitely
A significant amount of engineering went in to a solution that "waits for the CMS to start". The approach was as follows:
- Poll a broad range single easily-accessible endpoints and assert on expected functionality
- Require successive sequential successes before reporting OK
- Use backoffs and retries to achieve resilience during the boot process
- Restart the CMS and begin polling again when a defined timeout is reached
Some of the issues encountered were setting appropriate timeouts (especially as the application got slower and slower to boot as more things were added to it) and bizarre failure scenarios; in one case it was found that prematurely hitting the login page would cause the application to break forever, forcing a redeployment/reinstall.
This script started off really simple, and grew at a continuous rate throughout the whole project, ending up at 600 lines of Python. Just to check if the application had started.
Ping endpoints
When running a stack that sends a request through many reverse proxies, it's useful to be able to see what component in the stack are able to serve requests. It's also useful for healthchecks (specifically liveness probes, not that ALB distinguishes them from readiness probes) so that downstream failures do not cause cascading failures.
In Apache HTTPD this was achieved with:
Alias "/ping" "/var/www/html/ping"
<Directory /var/www/html/>
Options Indexes FollowSymLinks MultiViews
Require all granted
</Directory>
As well as a plaintext file at /var/www/html/ping containing "pong". This probably isn't required in a default HTTPD installation, but it was necessary for coexistence with the rest of the reverse proxying configuration.
In Nginx, it's even more simple:
location /nginx-health {
return 200 "healthy\n";
access_log off;
}
HMAC Encryption
An annoying "feature" that the application had was that it "encrypted" the contents of the CMS using a HMAC key that was stored on disk next to the content it was encrypting. I'll never understand why this was a thing; or so I'd like to say, but I understand that it exists only because it passes certain requirements from certain vendors that offer certain certifications. But - it's ineffective and offered no functionality other than burning up our man hours in trying to automate it away. It was problematic because we were re-attaching consistent volumes between instances, but the application would try to generate new HMAC keys when it was installed or booted without a key, so we'd have to try and trick it in to thinking that the key was already there.
For secrets storage, we had standardised on using AWS Systems Manager Parameter Store. Although AWS has an alternative service for storing secrets (AWS Secrets Manager), the dual purpose of it (secrets and config) as well as the simplicity appealed to me. Secrets Manager does have secrets rotation slightly integrated in to it (nothing magic - you're still going to have to write your own Lambda function for anything that's not a native AWS service), but that one feature doesn't justify the price point.
Now we were trying to automate away a feature we never asked for, but to make matters worse, the CMS was not making it easy - the path that the application would try to find the HMAC key at was not static and could change in between reboots. We would end up having to write ~100 lines of Python just to find the correct path and put the HMAC key in the correct location.
And finally, the application did not read this key after boot, so we were forced to reboot the application during deployment for it to successfully launch. This was an expensive operation, so we tried to optimise it where possible. In addition, there was no straightforward way to test whether or not we had the right HMAC key other than seeing if the website came up, so there were many occasions where we weren't sure whether or not it was working, and I don't think we were never confident as to whether or not this solution was workable.
Parameter Store caused some more problems later on too...
User/authentication Management
With some of the orchestration more closely related to the application, there was a requirement to have service accounts automatically created, as well as having credentials to privileged service accounts accessible to various scripts. AWS Systems Manager Parameter Store allows us to securely store credentials in an encrypted form, grant access with fine grained RBAC and easily retrieve them with 2-3 lines of code.
client = boto3.client("ssm")
response = client.get_parameter(
Name=f'/cms/{env}/admin-password',
WithDecryption=True
)
or in bash:
response="$(aws ssm get-parameter --region "ap-southeast-2" --with-decryption --name "/cms/${ENV}/admin-password")"
password="$(echo $response | jq --raw-output '.Parameter.Value')"
A script run on boot idempotently creates the service account with credentials fetched from Parameter Store, and scripts run after that that need to use the account can fetch the credentials. This works pretty well and is simple to implement.
But further requirements exponentially increase the complexity of the solution. We now have a requirement to automatically periodically rotate credentials. Because we only set the password once and never updated it, the credentials were effectively static, and started to be stored elsewhere (CI/CD systems, people's memory).
To achieve this, we have yet again borrowed from the concepts of Kubernetes and implemented these requirements as controllers.
The controller in question watches the (desired) state of [Parameter Store], where we store the credentials of the service accounts. It regularly compares what is in Parameter Store to the (current) state by authenticating as that user. If the current state is found to not match the desired state, we must update that account's password. This is where it got quite tricky, because this automation also needed to be applied to the superuser account, and we were trying to log in to account when the password we fetched was wrong.
Luckily, two things allow us to work around this:
- The password for the superuser that the application is delivered with (yes, it's configured with an insecure default). Therefore, we can loop
- Parameter Store stores the previous values (history) of a parameter
Therefore, we can implement a cron job to run a script that queries the history of the password, and tries each one starting from the most recent until the current password is set. Then, we can now log in with the current password, and then update it to the desired password.
More Controllers
In addition to syncing passwords, we also have a controller that asserts that the "cluster" is configured. I use the word "cluster", because for parts of the CMS, there must be a 1:1 mapping between individual servers (as opposed to using load balancing).
This 1:1 connectivity is also implemented as a cron job running a script on each EC2 instance which asserts that configuration for connectivity is configured appropriately, with some extra code to achieve this in an idempotent fashion.
Nginx TLS Termination
Because this application is (sort of) clustered, each individual server is significant (unlike a stateless, horizontally scaling, cloud-native application) and occasionally the ability to directly troubleshoot/communicate with each instance is required.
This oneliner was userful to generate a self-signed cert:
openssl req -x509 -newkey rsa:4096 -subj '/CN=localhost' -nodes -keyout /etc/pki/tls/private/localhost.key -out /etc/pki/tls/certs/localhost.crt -days 365 && \
One issue encountered with this was that some implementations of TLS required that the SAN value be correct, despite the fact that this certificate was never in any trust store to begin with.
Normally adding SAN configuration requires creating a configuration file, but using process substitution we can create add SAN attributes to the oneliner without it being too tedious:
<...> -extensions 'v3_req' -config <(cat /etc/pki/tls/openssl.cnf ; printf "\n[v3_req]\nkeyUsage = keyEncipherment, dataEncipherment\nextendedKeyUsage = serverAuth\nsubjectAltName = @alt_names\n[alt_names]\nDNS.1 = ${hostname}\nDNS.2 = localhost")
Another issue that a colleague found was the NSPOSIXErrorDomain:100 with HTTP/2, Nginx, Apache HTTPD and Safari.
Fixing it was matter of removing the header as suggested in the article:
Header unset Upgrade
Testing was more interesting, with the requests library not supporting HTTP/2. It raises questions in my mind whether it's appropriate to keep using this library given most things will be speaking HTTP/2. httpx seems like quite a good drop-in replacement despite being in beta, supporting the same API as requests.
import httpx
def test_cms_http2_upgrade_header():
client = httpx.Client(http2=True)
response = client.get(url=f"{url}/home")
assert "Upgrade" not in response.headers
Unix Signals
Whenever you perform a rolling update on an ASG and an instance is terminated, the kernel is sent a "hardware" signal to initiate a shutdown. The init system (likely systemd) receives this signal, and is responsible for propagating this signal to all services running on the operating system. These services should then propagate this signal to all their children processes so that they gracefully shut down; finish serving requests, save files to disk, etc.
This becomes important during connection draining; if you don't want your instance to sit around for the entire duration of the draining period, your applications should receive this signal and gracefully shut down. I've seen a lot of applications not do this. The most common causes are using intermediaries such as bash that don't necessarily pass signals to their children processes. Where possible, it helps to use exec or even dumb-init to launch processes that need to receive shutdown signals.
The application in question didn't have any of these problems, it just handled signals in a weird way that I would never have figured out if not for one small post on a dark corner of the internet.
Cache Invalidation
As a mostly-static website, caching in a Content Delivery Network (CDN) was a critical part of achieving a responsive website. The CDN of choice was AWS CloudFront, which can be described as a full-site caching reverse proxy. Because it is a full-site CDN (as opposed to one that is only used to deliver specific, static assets such as images, videos, javascript files, etc.) the content cached is not always long-lived and may need to be updated on-demand. This is where invalidation becomes extremely useful, as we can force a refresh of any asset on the CDN when the CMS determines than an update has been published.
Invalidating CloudFront can be pretty straightforward:
invalidate.py:
cloudfront.create_invalidation(
DistributionId=distribution_id,
InvalidationBatch={
"Paths": {
"Quantity": len(invalidation_paths),
"Items": invalidation_paths,
},
"CallerReference": caller_reference,
},
)
Where this became complex is:
- There was no one single trigger for content invalidation
- There was no correlation ID between each of the servers triggering their invalidation
- AWS does throttle the amount of concurrent invalidations at some point
- The stack involved other applications which were dependent on the CMS and were also making invalidations
To be able to deduplicate invalidations that occurred between servers without any kind of correlation ID, the best we could do was deduplicate based on time, with calls within a minute considered duplicates:
import time
unix_time = int(time.time())
caller_reference = unix_time - unix_time % 60
An alternative approach was to invalidate only from a server with a specific index assigned, but this had other implications given the architecture.
In the invalidation script, pattern matching was used on the path to invoke various workflows, such as paths that didn't quite match the provided path due to rewrite rules, invalidating APIs and triggering invalidation workflows in other systems.
Finally, functionality to invalidate a list of redirects caused some headache. A plaintext list of redirects (hundreds of them) was configured in the CMS, and httxt2dbm used to translate those in to Apache HTTPD redirect configuration. This took some additional engineering to create invalidations for, needing to parse the plaintext list of redirects and create an invalidation from that. This was fine, until we realised that the new list of redirects would not contain any redirects that were removed from the list, and therefore would persist for the TTL of that cache behaviour. This was resolved by keeping a list of redirects previously used and creating a union of the two to find out what needed to be invalidated.
Parameter Store Problems
If you've made it this far, you might remember that I earlier mentioned we'd later have problems with Parameter Store. To be fair, the issue was not entirely with us; we were sharing the account with numerous other applications which were also using Parameter Store.
We were hitting service limits. One day, all of a sudden, applications and scripts were failing when making Parameter Store calls. People were screaming left and right. We were making that many requests to Parameter Store that we were being rate limited by it. Requesting a service limit increase was easy enough to get us by while developing, but I wanted to ensure we'd have capacity in prod.
What happens in production when we have 1000x the number of requests?
I was a bit concerned but also a bit curious. Where were all these requests coming from?
How can we measure the source of Parameter Store calls? One method is to us CloudWatch Logs Insights.
CloudWatch Logs Insights is really useful for troubleshooting any issues related to CloudTrail, or really anything in CloudWatch Logs. It's not quite as featureful as Elastic Stack or Splunk, but it's good enough, and the best log aggregation tool is the one you have your logs in.
It's really simple to query on something like number of Parameter Store API calls by role:
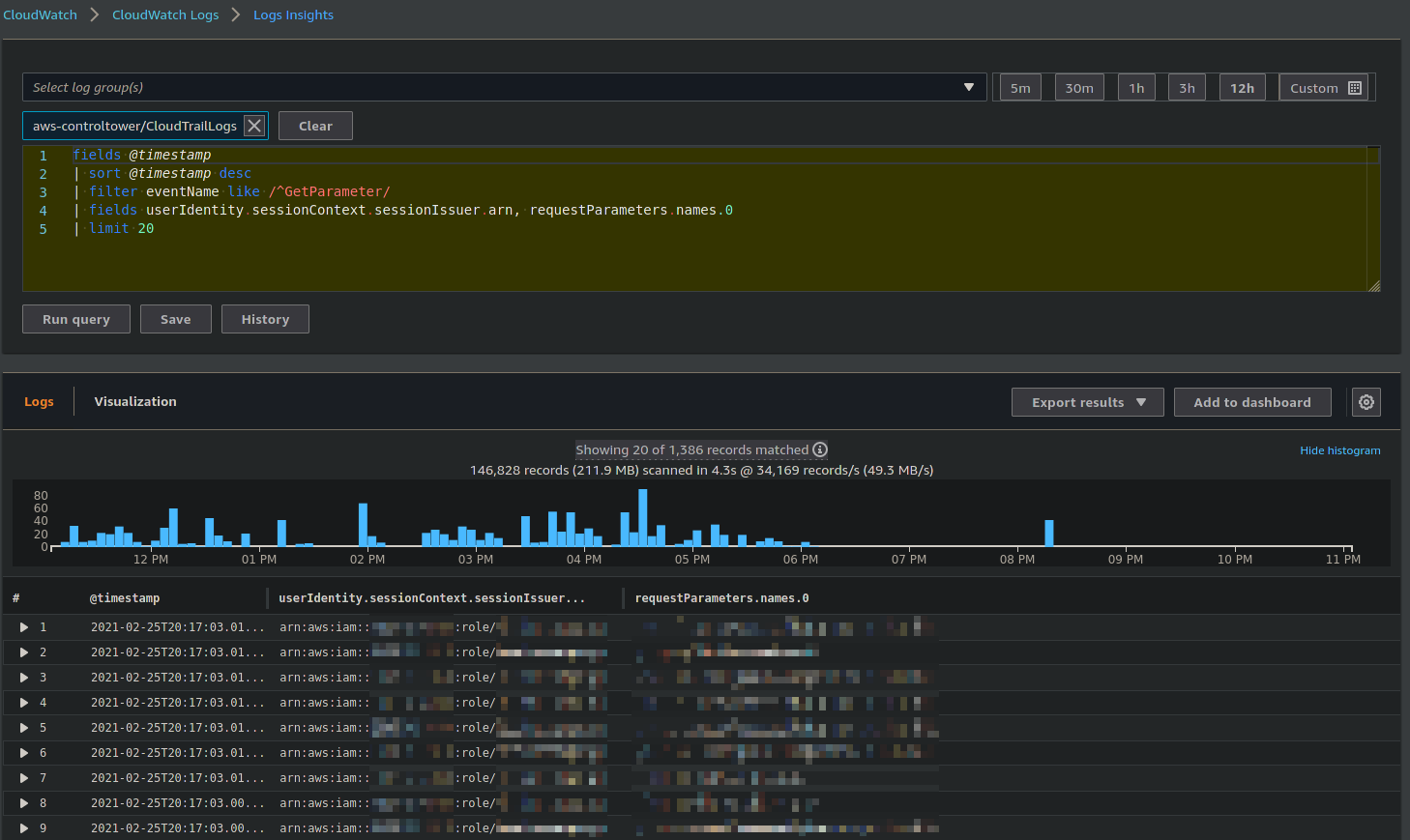
Again, it's not perfect as you can't even do something like bucket by role name over time and have it graphed. But it's good enough to get at least a vague grasp of where the majority of the offending API calls were coming from. Once we had this information, we were able to significantly optimise the number of calls we were making, to the point where we were well under the rate limits.
We also implemented retries and backoff almost everywhere while this was happening:
config = Config(
retries={
"max_attempts": 10,
"mode": "standard", # https://boto3.amazonaws.com/v1/documentation/api/latest/guide/retries.html#standard-retry-mode
}
)
ssm = boto3.client("ssm", config=config)
We still requested a massive service limit increase in our production account, just to be sure.
Testing
In an attempt to move towards Continuous Delivery, I strongly advocated for testing. Given that there was nothing to begin with, I put my foot forward with some throwaway examples to at least demonstrate an example of what it should look like and what it should achieve. I accidentally ended up setting the standard for language and testing framework, but in hindsight this actually worked out pretty well.
The framework used for testing was a combination of pipenv for dependency management and pytest for running the tests/assertions.
I'll break this up by the type of testing:
Smoke Tests
This is where the most important testing happened; we could tell very quickly whether certain things were working or not.
Ping
The most basic test, we assert that the webserver is reachable. If it does not pass, we fail the pipeline and do not continue promoting through each environment. We had a lot of environments.
import requests
def test_cms_ping_200():
r = requests.get(f"{cms}/ping")
assert "pong" in r.text
assert r.status_code == 200
Testing slightly more of the stack, we now asset on content in the CMS. Having both these tests us to tell at a glance when there is an issue with the CMS vs. an issue with the webservers.
def test_cms_content_200():
r = requests.get(f"{cms}/home")
assert "Welcome to the homepage!" in r.text
assert r.status_code == 200
CORS
As a CMS that would have assets loaded by many 3rd parties, asserting that we had the correct CORS behaviour allowed us to be confident in what can sometimes be a complex subject (read: nobody else was interesting in understanding CORS, so it fell to us to debug it).
def test_cms_cors_allow_google_com():
"""Ensure that https://google.com is permitted in CORS"""
origin = "https://google.com"
headers = {"Origin": origin}
r = requests.get(url=f"{cms}/logo.png", headers=headers)
assert r.headers["Access-Control-Allow-Origin"] == origin
assert r.status_code == 200
def test_cms_cors_deny_bad_actor():
"""Test access control origin for wicar.org, an example malicous website"""
origin = "https://wicar.org"
headers = {"Origin": origin}
r = requests.get(url=f"{cms}/logo.png", headers=headers)
assert "Access-Control-Allow-Origin" not in r.headers
assert r.status_code == 200
def test_cms_no_default_cors():
"""Test no origin header, no CORS"""
r = requests.get(url=f"{cms}/logo.png")
assert "Access-Control-Allow-Origin" not in r.headers
assert r.status_code == 200
A similar suite of tests were also added to the CloudFront pipeline given the nature of the configuring headers in CloudFront.
DNS
Because the index orchestration solution had been written explicitly for this solution, thoroughly testing it was critical to ensure we could rely on it and worry about other things.
def test_dns_matches_index():
"""Loop through all ASGs and all indexes within those ASGs and compare DNS records with tags"""
asg_names = ["app1", "app2", "app3"]
for asg_name in asg_names:
indexes = get_asg_indexes(asg_name) # get the _max_ indexes for that ASG
for index in indexes:
record = f"{index}-{asg_name}.example.com"
dns_ip = socket.gethostbyname(record) # actual DNS lookup
index_ip = get_instance_ip_by_index(
asg_name, index
) # IP of instance with index tag
assert dns_ip == index_ip
A similar test exists for EBS volumes, which also assets that they are tagged correctly.
E2E content creation test
While the smoke tests very efficiently give a picture of the application's current health, they do not necessarily stress the integrations between the components of the application.
This test is far more complex than any of the smoke tests, and also far more prone to being "flaky". A good amount of time was spent in to ensuring that this test was resilient to intermittent failures that we were not interested in worrying about, and only telling us when the integration between components had been broken by a change.
import pytest
import uuid
test_uuid = str(uuid.uuid4())
@pytest.fixture(scope="module") # invoke as setup for test functions
def setup_e2e():
wait_for_cluster_configuration() # wait for the controllers to finish configuring connectivity
delete_page() # ensure we are starting from scratch
pages = get_pages()
if "/smoketest" not in pages: # create page not idempotent
create_page(test_uuid=test_uuid)
replicate_content()
wait_for_replication()
yield # code after yield is teardown
delete_page()
# an example of using retries with backoff to make a test ignore intermittent unvailablility
@backoff.on_exception(
backoff.expo,
(
AssertionError,
requests.exceptions.HTTPError,
requests.exceptions.ReadTimeout,
KeyError,
json.decoder.JSONDecodeError,
),
max_time=120,
)
def create_page(uuid):
auth = get_auth()
r = requests.post(url, headers=headers, params={"action": "createPage", "title": test_uuid, auth=auth)
r.raise_for_status()
@pytest.mark.parametrize(
"execution_number", range(10)
) # test a few times to try hit a few different instances
def test_content(setup_e2e, execution_number):
url = f"{cms}/smoketest.html"
r = requests.get(url)
assert f"Smoke Test {test_uuid}" in r.text
assert r.status_code() == 200
The snippet above is quite abbreviated, but it demonstrates a few things:
- Using
pytest.fixtureto create a setup function for tests - Using
yieldin the setup to create teardown steps - Making the test resilient to uninteresting errors using the backoff library
- Using
pytest.mark.parametrizeto run a single test many times to ensure it fails if behaviour is not consistent - An end-to-end workflow of creating a page, invoking replication to test connectivity between components, testing the unique string (UUID) for this particular test and cleaning up afterwards
Unit Tests
Finally, we have unit tests. A lot of the work in unit testing code is put in to mocking external calls. These external calls are basically either requests or boto3.
To mock boto3:
def test_get_index():
"""get_index should retry query and return a number"""
client = boto3.client("ec2")
stubber = Stubber(client)
response = {
"Reservations": [
{"Instances": [{"InstanceId": "i-1234567890abcdef0", "Tags": []}]}
]
}
stubber.add_response("describe_instances", response)
response = {
"Reservations": [
{
"Instances": [
{
"InstanceId": "i-1234567890abcdef0",
"Tags": [
{
"Key": "index",
"Value": "1",
}
],
}
]
}
]
}
stubber.add_response("describe_instances", response)
stubber.activate()
assert (
index_orchestration.get_index(v_instance_id="i-abcdefgh1234", ec2=client)
== "1"
)
stubber.assert_no_pending_responses()
This test validates that the function can deal with the data returned from boto3, that it performs a retry when needed, and that it is not making unexpected API calls (assert_no_pending_responses()).
The trick to easily testing boto3 is to pass around clients as a parameter, or to inject a mock like so:
client = boto3.client("ssm")
stubber = Stubber(client)
with patch("boto3.client", return_value=client):
my_module.my_function()
To mock requests, the responses library is immensely useful:
import responses
@responses.activate
def test_home_page():
"""Assert that the origin is CMS when the response to /home is 200"""
event = origin_request_event # Lambda@Edge origin-request event
context = {}
responses.add(responses.HEAD, "https://cms-origin.example.com/home", status=200)
request = lambda_function.lambda_handler(event, context)
assert request["origin"]["custom"]["domainName"] == "cms-origin.example.com"
mock_file.assert_called()
assert len(responses.calls) == 1
This test validates that based on the response code returned by requests, the origin is modified to a particular domain name and no further requests are made. What is this Lambda function actually doing? See the [#Origin Routing Lambda] section below.
Configuration
Another use-case we had for testing is to test configuration, where an application accepts many different configurations but we want to enforce some behaviours.
One example was a situation where we were creating two very similar resources, but they needed separate configuration files. It would be very easy for these configuration files to drift, and if they did it would cause some unintuitive behaviour that would undoutably waste a lot of someone's time.
We could have also written something that templated a given file, which would ensure that the two were in sync (and I've done this many times before), but this was nice in that it meant both files were human-readable, easily distinguished and there was no abstraction on top of the files to manage.
def test_config_files_are_same():
with open("../config-1.yml", "r") as fh:
config_1 = yaml.safe_load(fh)
with open("../config-2.yml", "r") as fh:
config_2 = yaml.safe_load(fh)
# everything except the following fields should be the same
# if they're not, someone probably updated one without updating the other
keys_to_ignore = ["configuration_value_1", "some_other_config_key"]
delete_keys_from_dict(config_1, keys_to_ignore)
delete_keys_from_dict(config_2, keys_to_ignore)
assert config_1 == config_2
In retrospect this is pretty similar to something like conftest or Open Policy Agent, but instead of writing in rego we can leverage existing patterns and language to assert correct configuration.
Formatting
Not much to say here, other than pick a formatting tool, ideally one that has the least amount of configuration, and just stick with it. We found great success with black.
Pipeline
The pipeline for this application follows principles from trunk-based development; only commits to master trigger deployments to integrated environments. However, commits to all feature branches (that is, branches that aren't master) will trigger a pipeline that creates a review environment: a short-lived deployment of the application within the dev environment that has no inbound integrations. This concept is also known as a review app.
The pipeline roughly follows the following structure:
- Unit tests
- Build AMI
- Deploy dev and then system test dev
- Deploy staging, system test staging
- etc., repeat for each environment until production
One of the most unfortunate consequences of this approach for this particular application was the pipeline duration. I would normally like to say that 1 hour is approaching the limit of what I'd consider to be appropriate for CI/CD. In theory, the total pipeline duration doesn't actually matter if your deployment procedure is reasonably robust and has good feedback mechanisms, because you can simply not care about what happens once you've pushed your code (it will arrive in production eventually and you can feature toggle on your features at some stage). But no pipeline is ever bug free, and least of all this one. Because of the duration it took to boot the application, the feedback cycle was awful. This combined with enterprise requirements for an absurd 6 environments, the total pipeline duration was:
10 minutes per boot * (minimum) 3 reboots required to successfully launch the application:
30 minutes per instance
30 minutes per instance * 2 batches (MaxBatchSize) of instances:
60 minutes per environment
60 minutes per environment * 6 environments:
at least 6 hours from merge to production
This does not include tests, utility stages or failures that necessitated replaying deployments.
Review App Cleanup Lambda
As part of having a review app workflow, you need to consider review app cleanup. Cleanup can't be part of the pipeline, because it needs to happen asynchronously to any deployment activities. A developer will want to keep their review app running as long as their short-lived feature branch is alive, so it can't be tied to any of the events in a pipeline (e.g. finished deployment/testing) and it also shouldn't influence the outcome of the deployment. The event you want to clean up on is on branch deletion (either that, or successful merge of a pull request) or when a branch is "stale" and you just want to clean up (GitLab is the one exception here in that it does handle this kind of workflow).
Ideally a solution here can have two capabilities;
- The ability to trigger from webhooks (from your git provider)
- The ability to run on a schedule
Running on webhooks allows you to delete review apps when their respective branch is deleted, and running on a timer allows you to delete stale branches (with the caveat that you need to be able to determine how old resources are).
Admittedly, we didn't achieve this ideal state. Something that got us 90% of the way there was a Lambda function on a 1-day schedule that cleaned up all review apps. It adds some overhead to feature branches that take more than 1 day, but is otherwise kind of "good enough".
The implementation was as simple as
def handler(event, context):
clean_cms_stacks()
clean_ebs_pin_volumes()
clean_ebs_pin_snapshots()
clean_cms_dns_records()
where each function looked for specific naming conventions/tags to find related resources to clean up (and more importantly, to leave resources for other apps alone).
We achieved the cron cleanup reasonably well; this sufficed for I think 95% of scenarios. Webhooks would have been nice for the immediate cleanup on branch deletion but we never had the manpower to justify the implementation.
More significantly, we never did get around to implementing automated AMI cleanup. The complexity for this lies in figuring out what AMIs are currently in-use, which essentially necessitates scanning every account that might use the AMI. Looking around, I see no good OSS solutions for this either.
General Resilience
I've commented a few times on specific implementations of resilience and failure tolernace. These techniques were critical in making such a chaotic system work. Without them, we'd spend a lot more time restarting services and trying to get things in to a healthy state. Let me compile some of the techniques here:
- backoff: absolutely legendary library, swiss knife of making things resilient to failure
- boto3 retries: more specific to AWS API calls, this is a reasonably easy way to configure all API calls to retry more frequently than the defaults do
- systemd: can be used with systems like HTTPD or HAProxy that instantly fail on boot if downstream systems are not available
- docker run --restart=on-failure: great if you're running a bare docker container on an EC2 instance without using a container orchestration system
- And finally: cloud services. Delegate out to services like SNS or SQS and a lot of these concerns are handled for you.
Origin Routing Lambda
As part of a rush to deliver Minimum Viable Product (MVP) for this project, there was very little consideration for the routing capabilities that come with CloudFront out of the box. CloudFront really only does routing based on prefix (it can do a wildcard in the middle of the path, but most behaviours I've seen are prefix match).
Here we had two separate origins. A path e.g. /blog would route traffic to the main origin (the CMS), with all pages under it going to that origin e.g. /blog/my-page. The complication was when there was a requirement for arbitrary pages to route to the alternate origin under the same prefix, e.g. /blog/other-page, without changing the CloudFront behaviour configuration. The requirement for not changing the cache behaviours in CloudFront was needed for two reasons:
- It required a code change, which was not always accessible to the individuals that were updating pages in the CMS
- The number of pages required far exceeded the soft limit for the number of cache behaviours and even if we increased them, it did not seem sustainable going forward
This was pretty problematic and things didn't look too good. We were able to start thinking of solutions by rephrasing the problem slightly:
I want CloudFront to serve pages from an alternate origin when they exist, and serve pages from the main origin only when they are absent in the alternate origin
One solution was origin failover with Origin Groups which happened to have the right behaviour for routing between origins, but something told me that using this solution that was designed for highly available infrastructure to implement business logic wasn't the right way to go. I'm glad we made this call, because in hindsight it would not have worked out (keep reading).
Ultimately we landed on Lambda@Edge (L@E). There are even examples in the official documentation for this use-case, so it seemed like the right way to go. To elaborate on how this would work when a user requested a page from CloudFront:
- A user hits a certain path
- This path is registered with an origin-request L@E
- The L@E is invoked, passing the details of the original request to the handler
- The L@E inspects the details of the original request, determines the path and makes a "preflight" request to the alternate origin
- If the page exists in the alternate origin, the target origin is changed to the alternate origin
- If the page does not exist, leave the origin configuration as-is (main origin)
This solution has a few benefits:
- It required no code changes when a page from the alternate origin needed to be displayed (as opposed to having to e.g. upload a list of pages to display somewhere for the L@E to read)
- By configuring the L@E as origin-request, it is only triggered when the response is not in cache
- By using a
HEADrequest for the prelight check, the amount of data transferred from the origin is minimal, resulting in a very low overhead (50-100ms) - By having this logic in code (as opposed to an out of the box solution like origin failover) we were able to have flexibility in the logic. This was a double-edged sword, with any kind of logic adding significant cognitive burden to the overall solution.
This worked surprisingly well. It took a lot of time to convince some of the architects in the organisation that this would fulfill all the requirements of the solution, and even then I'm not sure they were necessarily convinced but rather baffled with bullshit. But it all worked out. The decision to go with code over trying to retrofit an infrastructure solution to meet our needs was a good choice, as the flexibility allowed us to meet unforeseen edge cases and requirements.
One such example was paths ending in .html. Because the CMS did a naive redirect where it stripped file extensions, the L@E always reported there was content there (a 301/302 counted as "existing"). This meant that any URL intended to go to the alternate origin that ended in .html ended up erroneously routed to the main origin. Because we were in control of the logic of this routing, we were able to put in a workaround.
I worry what this solution will look like in a few years time given it can be extended and made indefinitely more complex, but I'm not convinced there was any better alternative.
CloudFront, WAF and Lambda@Edge IP Ranges
The strategy above worked well in some adhoc testing, but when we integrated it in to one of our nonprod environments, CloudFront immediately stopped serving pages. The problem? It couldn't access the origin.
CloudFront Origin Protection and Security Groups
Origin protection is a term used to describe techniques that prevent bypassing a CDN. If your CDN provides caching, DDOS protection, WAF, etc., then allowing anyone to go straight past that and hit the origin directly is not ideal.
Traditionally, you would be able to add CloudFront IP ranges to a Security Group (SG), and attach that SG to your load balancer. You could automate this by parsing the ip-ranges.json document that AWS provides, which lists all the IPs of CloudFront. You could even have a Lambda trigged via SNS whenever this documented changed so that the list was always up to date, even when AWS added new edge locations.
But at some point, the number of CloudFront CIDR ranges started to exceed the limit of rules for a security group, which necessitated some tedious workarounds. There was another problem, in that whitelisting CloudFront meant that any distribution could access your origin - not just yours.
Also, IP whitelisting is nearly always a terrible solution in general.
But we had already implemented IP whitelisting, and for the most part it was fine. Now, when we added Lambda@Edge, we'd also need it to be whitelisted - since it needs to directly contact the origin. This was fine though, since as anyone would assume, surely Lambda@Edge, which executes in the context of the CloudFront edge servers, would have a source IP of CloudFront? Right? It should just automatically work.
Wrong.
Unintuitively, outbound traffic originating from a Lambda@Edge function has a source IP that falls in the range of the EC2 service; IPs from the same range that your EIPs or NAT gateways would use. In retrospect, this might make sense given that historically you could not send arbitrary traffic from CloudFront IP ranges and a malicious actor could potentially use that in creative ways.
CloudFront Origin Protection and WAF
When I realised I'd made an oversight here I wasn't particularly concerned (well okay, a little bit), as there's a much better way to do origin protection anyway. By configuration a "secret" header in the CloudFront distribution configuration, we can also configure WAF on the origin's ALB to drop all requests not containing this exact header. Unless you know the value of this secret header, WAF will block all requests you make to it.
This approach is nice, because:
- It denies other CloudFront distributions
- As a Cloud Engineer, you can e.g. test access to the origin from your workstation (as long as you have access to the secret)
- You can grant other systems access to the origin (!)
Now all we had to do was include the secret header in calls made by the Lambda@Edge function and it would no longer be blocked.
I will say that this method isn't perfect either: CloudFront does not actually have a concept of a "secret header", so the value is retrievable by anyone that has permission to retrieve the distribution configuration. There's also no way to use secret variables in Lambda@Edge (and API calls to Parameter Store would be too slow), so as a workaround it was included as part of the package (at least it's not visible in the AWS console...).
Conclusion
There is no one particular conclusion to this. The project did reach production eventually which to some may not be a high bar to hit, but given the constraints and boundaries we had to work in, it was still satisfying for me. Perhaps the only regret I have is the amount of time, effort, blood, sweat and tears we dedicated to trying to automate this piece of software when it probably would have been less work to manage it the old school way - as a pet.